BeautifulSoup le parser HTML Python
BeautifulSoup est une bibliothèque Python permettant de parser du HTML de manière très simple et de façon tolérante aux erreurs (il n’assertera pas en cas d’erreur HTML).
Dans cet article, je vais vous expliquer comment récupérer la filmographie de Charles Chaplin depuis la fiche acteur du site IMDb, de manière simple et efficace. Vous retrouverez les sources utilisées pour cet article dans le dépôt Github IMDB-scraper.
Installation de BeautifulSoup
Pour tester BeautifulSoup, je vous conseille l’utilisation d’un environnement virtuel afin d’éviter de modifier votre environnement système mais ceci est facultatif.
$ cd /path/to/project $ pyvenv env $ source env/bin/activate
L’installation de BeautifulSoup peut se faire de différentes manières, via pip notamment dans le cas d’utilisation d’un environnement virtuel ou encore via apt-get sous les systèmes de base Debian. Dans tous les cas, vous devrez avoir une version de python supérieur à la 2.6. L’ensemble du code de l’article, a été exécuté sous Python 3.4 certaines adaptations sont donc nécessaire pour l’exécuter sous Python 2.
$ pip install beautifulsoup4 # apt-get install python3-bs4 # apt-get install python-bs4
Utilisation concrète
Dans cette partie, nous verrons comment récupérer tous les films où Charles Chaplin a joué en prenant comme source d’information le site IMDb. Avant toute chose, nous devons récupérer l’adresse de la fiche de Charles Chaplin sur le site de IMDb. Nous pourrions le faire de manière automatique mais ce n’est pas le but ici, vous trouverez cette fonction sur le dépôt Github.
La fiche de Charles Chaplin a pour url : http://www.imdb.com/name/nm0000122/.
Maintenant que l’url de la fiche est connue, il nous faut récupérer un tag, une class ou encore un id qui nous permet de différencier les balises entourant les films dans lequel il a tourné de toutes les autres informations présentes sur la page.
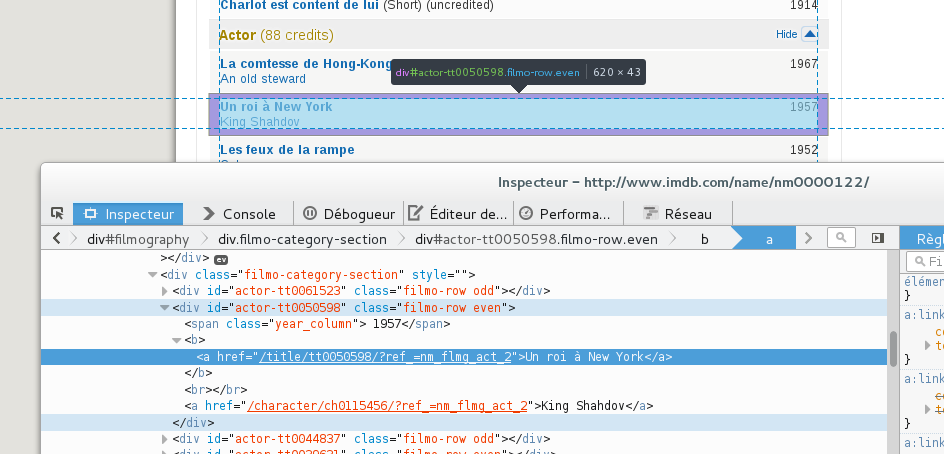
Dans la copie d’écran précédente, nous pouvons voir que les films, où il a été acteur, sont contenus dans un div ayant un id commençant par actor-. Nous voyons aussi que l’année du film est présente dans un sous-élément ayant dans l’attribut class la valeur year_column et le nom du film est contenu dans un balise <b>. Nous avons maintenant tous les éléments pour récupérer nos données et cela nous donne le morceau de script suivant :
import bs4
import re
import urllib.request
actor_url = 'http://www.imdb.com/name/nm0000122/'
with urllib.request.urlopen(actor_url) as f:
data = f.read().decode('utf-8')
soup = bs4.BeautifulSoup(data, 'html.parser')
for d in soup.find_all(id=re.compile('^actor-.*')):
year = d.find(class_='year_column').get_text(' ', strip=True)
name = d.b.get_text(' ', strip=True)
print(year, name)
- En ligne 7 et 8, nous récupérons la trame de la page HTML du site.
- En ligne 9, nous demandons à BeautifulSoup d’intégrer la page afin de pouvoir la traiter.
Rentrons maintenant dans la puissance de beautifulSoup.
- En ligne 11, nous recherchons l’ensemble des éléments ayant un
idcommençant paractor-. Comme vous pouvez le constater BeautifulSoup accepte l’utilisation d’expressions régulières en entrée ce qui nous permet de faire des recherches très précises. Nous parcourons l’ensemble des réponses. - En ligne 12, nous demandons de nous fournir le contenu textuel du premier élément ayant comme classe
year_column. - En ligne 14, nous récupérons le texte contenu au sein de la balise
<b>.
Voilà en 14 lignes, nous avons parsé un fichier HTML de 9440 lignes et récupéré juste les informations qui nous intéressaient. Tout cela grâce à la magie du Python et de la bibliothèque BeautifulSoup. J’espère que ce sujet vous aura intéressé. N’hésitez pas à partager avec nous vos différentes utilisations de cette bibliothèque magique.
Commentaires
gawel
PHP fait ça en natif avec DOMXPath :p
Taquinerie mise à part, intéressant, si un jour je me mets à Python, ça me sera surement très utile 😉
Anthony
En effet Gawel, PHP le fait en natif et au vu de son utilisation dans le Web, je dirais fort heureusement.
Cependant à comparer, le Python est quand meme plus jolie, non ? 😀
<?php $file = "http://www.imdb.com/name/nm0000122/"; $doc = new DOMDocument(); $doc->loadHTMLFile($file); $xpath = new DOMXpath($doc); $elements = $xpath->query("//*/div[@id[starts-with(., 'actor-')]]"); if (!is_null($elements)) { foreach ($elements as $e) { $year = trim($xpath->query('span[@class="year_column"]', $e)[0]->nodeValue); $name = trim($xpath->query('b', $e)[0]->nodeValue); echo $year . $name; } }